![]()
广州市天河区黄埔大道中260号恒安大夏恒乐轩19G
电话:020-85625352
手机:18102256923、18102253682
Email:servers@gzscbio.com
Fax:020-85625352
QQ:386244141
项目名称:circRNA测序及分析报告
所属分类:生物信息学分析
联系电话:020-85625352
QQ:386244141
Email:servers@gzscbio.com
技术服务描述
circRNA测序及分析报告
生信部
2020年12月29日
1. CircRNA背景及分析流程简介
1.1. 背景简介
环形RNA是一类在真核生物中广泛存在的具有特殊环状结构的非编码RNA分子。已有文献表明,在生物体内,环形RNA有着miRNA海绵、RBP海绵以及翻译短肽等多项功能,在许多生物学过程中发挥着重要作用。 目前研究表明,大部分环形RNA来源于蛋白编码基因的外显子区域。在pre-mRNA剪接的过程中,除典型的内含子剪接事件外,还可能会发生5’端到3’端的反向剪接事件,从而形成环形RNA。因此,剪接产物中环形RNA所占比例是环形RNA分析的重要指标之一,具有高成环比例的环形RNA分子,可能具有更加重要的生物学功能。 同时,同一基因内部也可能产生多种不同的环形RNA,基因内对环形RNA产生位点的使用偏好,也在一定程度上反映了转录过程对环形RNA产生的调控。因此,环形RNA转录本水平的准确定量,是目前环形RNA分析的重要基础。
为了解决该问题,赵方庆团队开发了一个新的环形RNA分析算法。根据已有工具鉴定出的环形RNA成环位点信息,研究人员重构了具有反向剪接特征的环形RNA参考序列,简化了复杂的反向剪接位点比对问题,并结合测序读段比对到参考基因组和环形序列的结果,筛选出了高置信度的来自环形RNA的读段,解决了目前环形RNA识别和定量方法中准确度低和假阳性率高的问题。作者在模拟数据和真实转录组数据中,对多种常用环形RNA识别软件的表现进行了综合评估,发现该研究中开发的方法在环形RNA表达量和成环比例的计算中,均取得了最佳的结果。
1.2. 信息分析流程
RNA-seq的核心是基因表达差异的显著性分析,使用统计学方法,比较两个条件或多个条件下的基因表达差异,从中找出与条件相关的特异性基因,然后进一步分析这些特异性基因的生物学意义,分析过程包括质控、比对、定量、差异显著性分析、功能富集等环节。信息分析流程如下图所示:
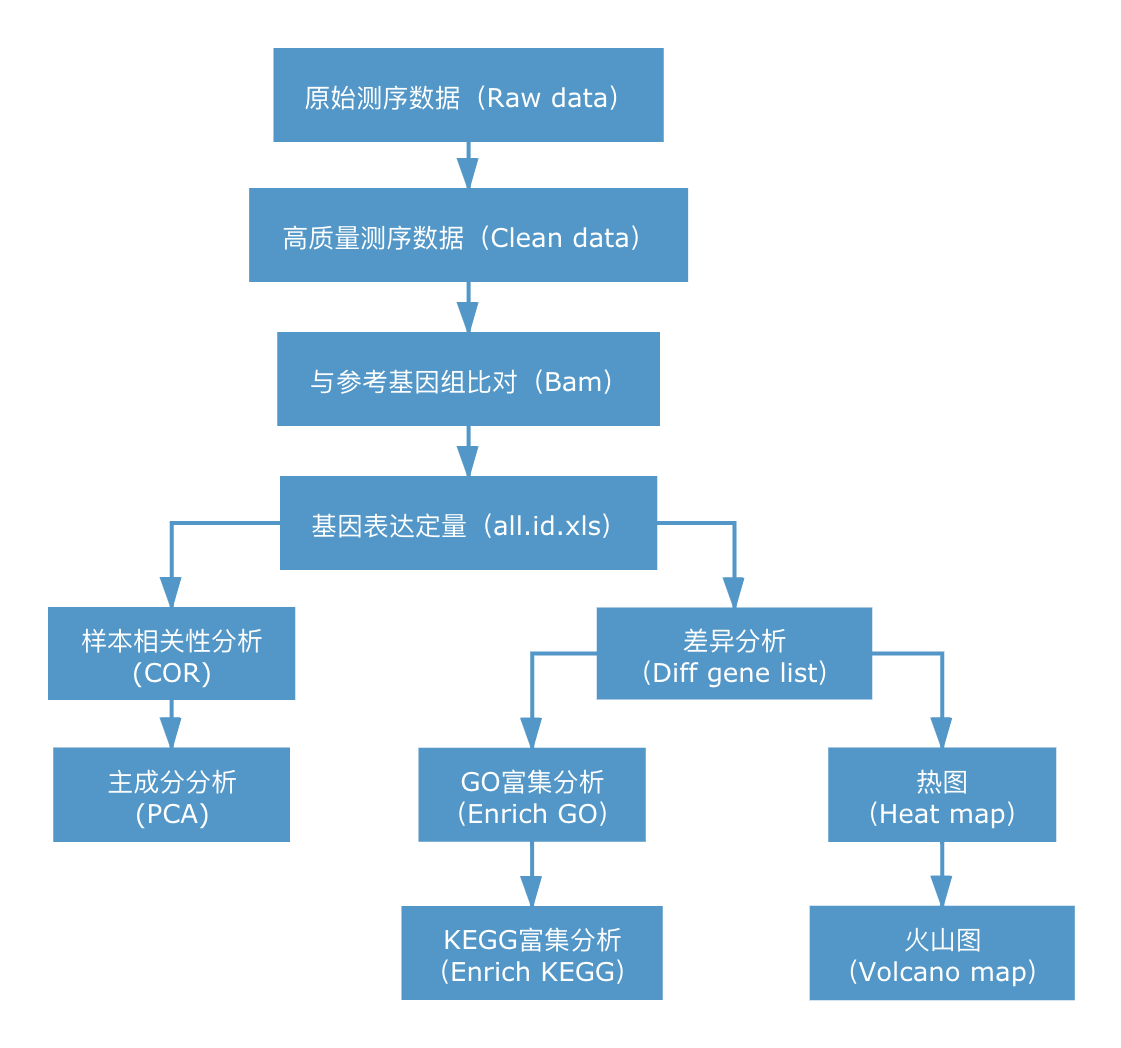
2. 信息分析
2.1. 测序数据质量控制
对原始测序数据及去除接头后的可用数据进行质量评估。测序数据一般为双端测序,因此,每个测序样本会有两个测序结果。
评估的具体内容见:
RawData-fastqc 文件链接: /result/qc/qc_rawdata/*.html
CleanData-fastqc 文件链接: /result/qc/qc_cleandata/*.html
Fastqc 格式补充说明: /result/qc/qc_Supplement.html
2.2. 参考基因组比对
测序片段(fragments)是mRNA随机打断的,为了确定这些一段由哪些基因转录来,需要将质控后的clean reads比对到参考基因组上。使用HISAT2软件将Clean Reads与参考基因组进行快速精确的比对,获取Reads在参考基因组上的定位信息[4]。HISAT2软件官方手册。
如果参考基因组组装的较为完善,而且所测物种与参考基因组一致,且相关实验不存在污染,那么实验所产生的测序reads成功比对到基因组的比例会高于70% (Total Mapped Reads or Fragments)。本项目所用参考基因组为 hg38 ,下载链接:Homo_sapiens.GRCh38.dna.primary_assembly.fa.gz,基因组结构注释文件:Homo_sapiens.GRCh38.90.gtf.gz。
结果文件:
各个样本的比对情况统计文件:
/result/map_stat/*.flagstat.txt
2.3. 定量分析
2.3.1. 基因表达定量
我们对每个样本分别进行基因表达水平的定量分析,再合并得到所有样本的表达矩阵,第一列为基因的ID,其余列为各样本的原始read count值,seqname列之后为该基因注释信息。
表格说明:
| 表头 | 说明 |
|---|---|
Geneid | 基因名 |
Samples_name* | 样本的表达矩阵原始read count值 |
... | 同上 |
seqname | 基因所在的染色体名称 |
start | 基因所在染色体的起始位置 |
end | 基因所在染色体的终止位置 |
strand | 基因所在染色体的正负链信息 |
ENSEMBL | 基因名称ENSEMBL |
SYMBOL | 基因名称SYMBOL |
biotype | 基因注释中对应的biotype |
description | 基因功能描述 |
结果文件:
原始表达矩阵及注释结果:
result/Quant/gene_counts.xls
2.3.2. 样本间相关性
生物学重复通常是任何生物学实验所必须的,目前主流期刊也基本要求生物学重复。生物学重复主要有两个用途:一个是证明所涉及的生物学实验操作不是偶然,而是可重复的。另一个是为了确保后续的差异基因分析得到更可靠的结果。样品间基因表达水平相关性是检验实验可靠性和样本选择是否合理的重要指标。相关系数越接近1,表明样品之间表达模式的相似度越高。Encode计划建议皮尔逊相关系数的平方(R2)大于0.92(理想的取样和实验条件下)。具体的项目操作中,我们要求生物学重复样品间R2至少要大于0.8,否则需要对样品做出合适的解释,或者重新进行实验。根据各样本所有基因的表达值计算组内及组间样本的相关性系数,绘制成热图,可直观显示组间样本差异及组内样本重复情况。样本间相关性系数越高,其表达模式越为接近,样本相关性热图如下图所示。
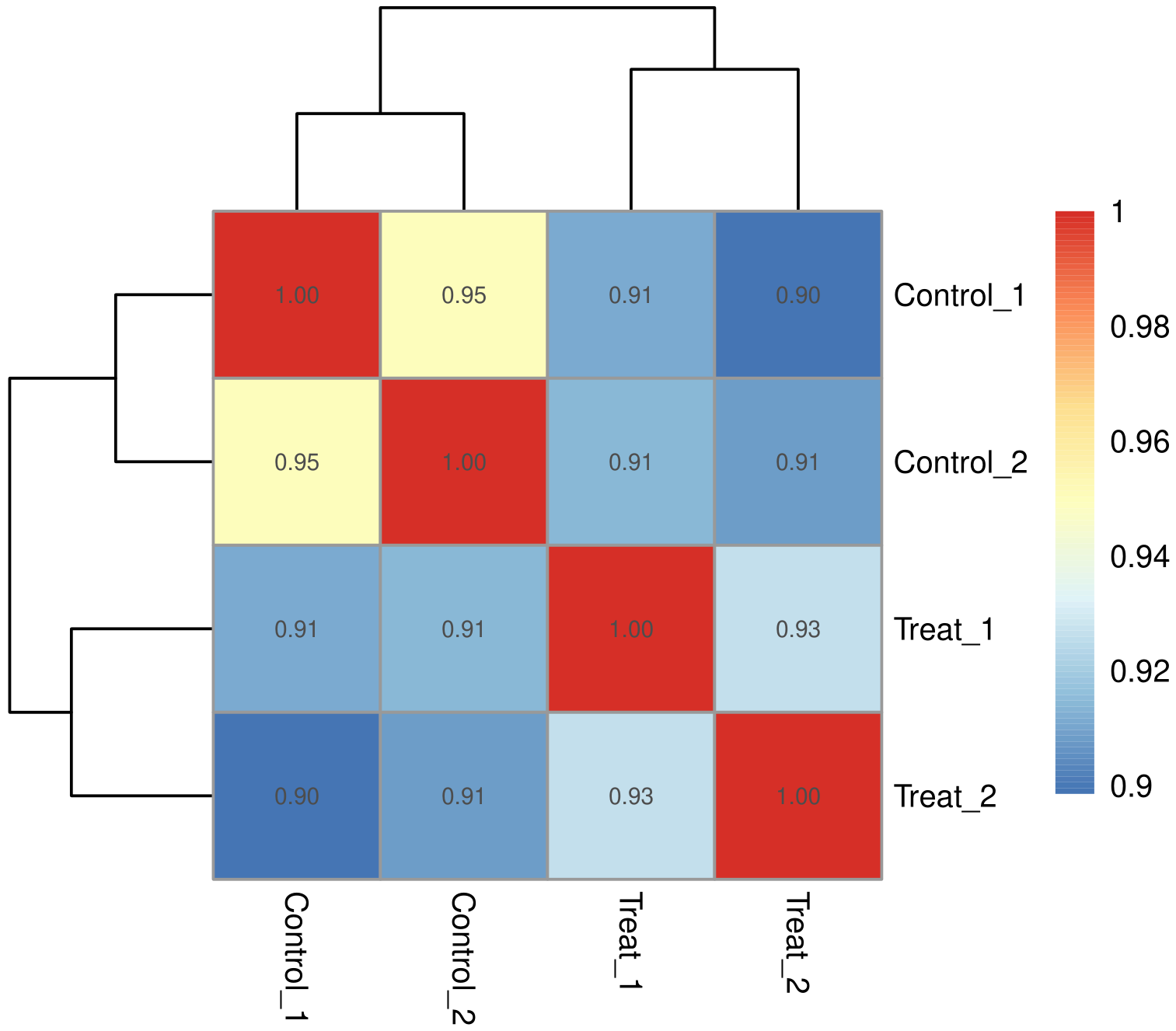
图 1 样本间相关性热图
图中横纵坐标为各样本相关系数的平方
结果文件:
样本间相关性热图结果:Quant/cor_pheatmap*
2.3.3. 主成分分析
主成分分析(PCA)也常用来评估组间差异及组内样本重复情况,PCA采用线性代数的计算方法,对数以万计的基因变量进行降维及主成分提取。我们对所有样本的基因表达值进行PCA分析,如下图所示。理想条件下,PCA图中,组间样本应该分散,组内样本应该聚在一起。
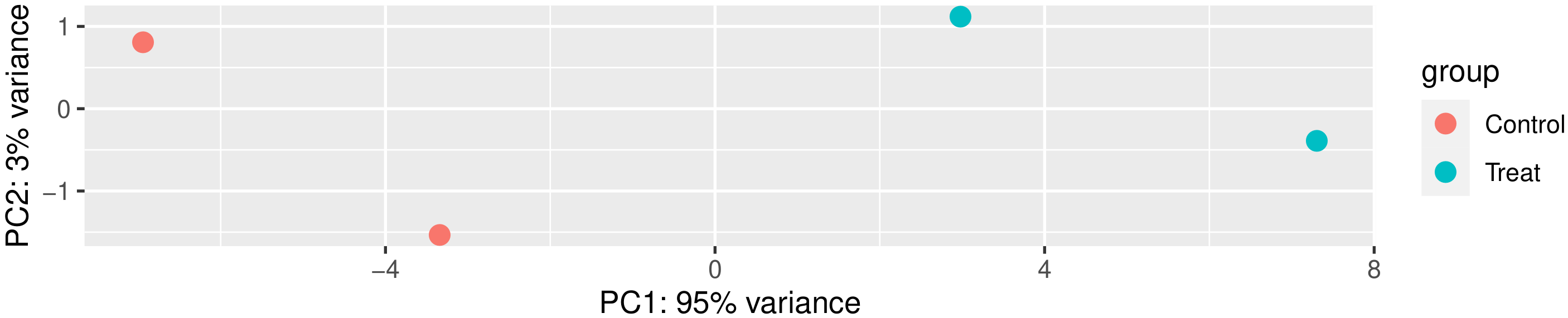
图 2 主成分分析结果图
图中横坐标为第一主成分,纵坐标为第二主成分
结果文件:
主成分分析结果:Quant/pca*
2.4. 差异分析
基因表达定量完成后,需要对其表达数据进行统计学分析,筛选样本在不同状态下表达水平显著差异的基因。差异分析主要分为三个步骤。
首先对原始的readcount进行标准化(normalization),主要是对测序深度的校正。
然后统计学模型进行假设检验概率(pvalue)的计算
最后进行多重假设检验校正,得到FDR值(错误发现率,padj是其常见形式)[1-2]。
针对不同的实验情况,我们选用合适的软件进行基因表达差异显著性分析,具体如下表所示。
表1 表达差异分析所用软件及差异基因筛选标准
| 类型 | 软件 | 标准化方法 | pvalue计算模型 | FDR计算方法 | 差异基因筛选标准 |
|---|---|---|---|---|---|
| 有生物学重复 | DESeq2(Anders et al, 2014) | DESeq | 负二项分布 | BH | |log2(FoldChange)| > 0 & padj < 0.05 |
| 无生物学重复 | edgeR(Robinson et al, 2010) | TMM | 负二项分布 | BH | |log2(FoldChange)| > 1 & padj < 0.05 |
若按照以上标准筛选得到的差异基因过少(低于100),很有可能导致后面的功能富集分析没有显著性结果,所以,我们会根据项目的具体情况,适当地降低筛选差异基因的阈值标准。若项目实验只关注某几个基因的表达情况(如基因敲除),不在意富集结果,从下面的差异分析表格中筛选关注的那几个基因即可。
一般来说,如果一个基因在两组样品中的表达量差异达到两倍以上,我们认为这样的基因是具有表达差异的。为了判断两个样品之间的表达量差异究竟是由于各种误差导致的还是本质差异,我们需要对所有基因在这两个样本中的表达量数据进行假设检验。而转录组分析是针对成千上万个基因进行的,这样会导致假阳性的累积,基因数目越多,假设检验的假阳性累积程度会越高,所以引入padj对假设检验的P-value进行校正,从而控制假阳性的比例[3]。
差异基因的筛选标准是非常重要的,我们给出的标准|log2(FoldChange)| > 1 & padj< 0.05是常用的经验值,在实际项目中可以根据情况灵活选择。例如,差异倍数可以选择1.5倍,也可以选择3倍,padj常用的阈值包括0.01、0.05、0.1等。若按照以上标准筛选得到的差异基因过少,很有可能导致后⾯的功能富集分析没有显著性结果。若项目实验只关注某几个基因的表达情况(如基因敲除),不在意富集结果,从下面的差异分析表格中筛选关注的那几个基因即可。反之,如果得到的差异基因数目过多,不利于后续目标基因的筛选,这个时候可使用更严格的阈值标准进行筛选,则可以使用更严格的阈值标准进行筛选。
2.4.1. 差异基因的筛选
通过Deseq2进行差异分析,我们通常采用 |log2FC|>1 & padj < 0.05 进行差异基因的筛选,随后对差异基因进行注释,得到包含注释信息的差异基因列表。
结果文件:
差异基因列表及相关注释信息(筛选结果):result/Enrichment/Allgene_anno.xls
差异基因列表及相关注释信息(总的结果):result/Enrichment/Allgene_anno_ALL.xls
Differential/Allgene_anno*.xls表头
| 表头 | 说明 |
|---|---|
ENSEMBL | 差异基因的ENSEMBL名 |
pvalue | 差异基因的置信度计算结果 |
padj | 差异基因的多重校验FDR |
log2FC | Treat组 vs Control组 差异倍数 的log2标准化结果 |
FC | Treat组 vs Control组 差异倍数 |
log2FC_abs | Treat组 vs Control组 差异倍数 的log2标准化结果的绝对值(此列便于筛选log2FC阈值) |
FC_HvsL | 高表达组 vs 低表达组 差异倍数 (此列便于筛选FC阈值) |
change | 使用本次分析的阈值,对差异基因的上下调标记 |
ENSEMBL | 同上 |
SYMBOL | 差异基因的SYMBOL名 |
description | 差异基因的基本描述信息 |
baseMean | 差异基因的表达量标准化后的平均值 |
Samples* | 样本的原始表达矩阵表达量结果 |
Samples*_normal | 样本的表达矩阵标准化后的结果 |